
和存储引擎层。
Server层的架构对于不同的存储引擎来讲都是一样的,包括连接/线程处理、查询处理(parser、optimizer)以及其他系统任务。存储引擎层有很多种,mysql提供了存储引擎的插件式结构,支持多种存储引擎,用的最广泛的是innodb和myisamin;inodb主要面向OLTP方面的应用,支持事务处理,myisam不支持事务,表锁,对OLAP操作速度快。
以下主要针对innodb存储引擎做相关介绍。
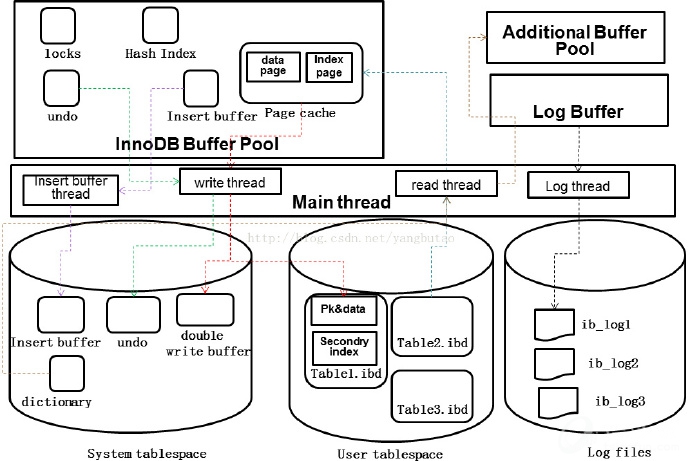
在线程处理方面,Mysql是多线程的架构,由一个master线程,一个锁监控线程,一个错误监控线程,和多个IO线程组成。并且对一个连接会开启一个线程进行服务。io线程又分为节省随机IO的insert buffer,用于事务控制的类似于oracle的redo log,以及多个write,多个read的硬盘和内存交换的IO线程。
在内存分配方面,包括innodb buffer pool ,以及log buffer。其中innodb buffer pool包括insert buffer、datapage、index page、数据字典、自适应hash。Log buffer用于缓存事务日志,提供性能。
在数据结构方面,innodb包括表空间、段、区、页/块,行。索引结构是B+tree结构,包括二级索引和主键索引,二级索引的叶子节点是主键PK,根据主键索引的叶子节点指向存储的数据块。这种B+树存储结构可以更好的满足随机查询操作IO要求,分为数据页和二级索引页,修改二级索引页面涉及到随机操作,为了提高写入时的性能,采用insert buffer做顺序的写入,再由后台线程以一定频率将多个插入合并到二级索引页面。为了保证数据库的一致性(内存和硬盘数据文件),以及缩短实例恢复的时间,关系型数据库还有一个checkpoint的功能,用于把内存buffer中之前的脏页按照比例(老的LSN)写入磁盘,这样redolog文件的LSN以前的日志就可以被覆盖了,进行循环使用;在失效恢复时,只需要从日志中LSN点进行恢复即可。
在事务特性支持上,关系型数据库需要满足ACID四个特性,需要根据不同的事务并发和数据可见性要求,定义了不同的事务隔离级别,并且离不开对资源争用的锁机制,要避免产生死锁,mysql在Server层和存储引擎层做并发控制,主要体现在读写锁,根据锁粒度不同,有各个级别的锁(表锁、行锁、页锁、MVCC);基于提高并发性能的考虑,使用多版本并发控制MVCC来支持事务的隔离,并基于undo来实现,在做事务回滚时,也会用到undo段。mysql 用redolog来保证数据的写入的性能和失效恢复,在修改数据时只需要修改内存,再把修改行为记录到事务日志中(顺序IO),不用每次将数据修改本身持久化到硬盘(随机IO),大大提高性能。
在可靠性方面,innodb存储引擎提供了两次写机制double writer用于防止在flush页面到存储上出现的错误,解决磁盘half-writern的问题。
Ø 对于高并发高性能的mysql来讲,可以在多个维度进行性能方面的调优。
a、硬件级别,
日志和数据的存储,需要分开,日志是顺序的写,需要做raid1+0,并且用buffer-IO;数据是离散的读写,走direct IO即可,避免走文件系统cache带来的开销。
存储能力,SAS盘raid操作(raid卡缓存,关闭读cache,关闭磁盘cache,关闭预读,只用writeback buffer,不过需要考虑充放电的问题),当然如果数据规模不大,数据的存储可以用高速的设备,Fusion IO、SSD。
对于数据的写入,控制脏页刷新的频率,对于数据的读取,控制cache hit率;因此而估算系统需要的IOPS,评估需要的硬盘数量(fusion io上到IOPS 在10w以上,普通的硬盘150)。
Cpu方面,单实例关闭NUMA,mysql对多核的支持不是太好,可以对多实例进行CPU绑定。
b、操作系统级别,
内核以及socket的优化,网络优化bond、文件系统、IO调度
innodb主要用在OLTP类应用,一般都是IO密集型的应用,在提高IO能力的基础上,充分利用cache机制。需要考虑的内容有,
在保证系统可用内存的基础上,尽可能的扩大innodb buffer pool,一般设置为物理内存的3/4
文件系统的使用,只在记录事务日志的时候用文件系统的cache;尽量避免mysql用到swap(可以将vm.swappiness=0,内存紧张时,释放文件系统cache)
IO调度优化,减少不必要的阻塞,降低随机IO访问的延时(CFQ、Deadline、NOOP)
c、server以及存储引擎级别(连接管理、网络管理、table管理、日志)
包括cache/buffer、Connection、IO
d、应用级别(比如索引的考虑,schema的优化适当冗余;优化sql查询导致的CPU问题和内存问题,减少锁的范围,减少回表扫描,覆盖索引)
Ø 在高可用实践方面,
支持master-master、master-slave模式,master-master模式是一个作为主负责读写,另外一个作为standby提供灾备,maser-slave是一个作为主提供写操作,其他几个节点作为读操作,支持读写分离。
对于节点主备失效检测和切换,可以采用HA软件,当然也可以从更细粒度定制的角度,采用zookeeper作为集群的协调服务。
对于分布式的系统来讲,数据库主备切换的一致性始终是一个问题,可以有以下几种方式:
a、集群方式,如oracle的rack,缺点是比较复杂
b、共享SAN存储方式,相关的数据文件和日志文件都放在共享存储上,优点是主备切换时数据保持一致,不会丢失,但由于备机有一段时间的拉起,会有短暂的不可用状态
c、主备进行数据同步的方式,常见的是日志的同步,可以保障热备,实时性好,但是切换时,可能有部分数据没有同步过来,带来了数据的一致性问题。可以在操作主数据库的同时,记录操作日志,切换到备时,会和操作日志做个check,补齐未同步过来的数据;
d、还有一种做法是备库切换到主库的regolog的存储上,保证数据不丢失。
数据库主从复制的效率在mysql上不是太高,主要原因是事务是严格保持顺序的,索引mysql在复制方面包括日志IO和relog log两个过程都是单线程的串行操作,在数据复制优化方面,尽量减少IO的影响。不过到了Mysql5.6版本,可以支持在不同的库上的并行复制。
Ø 基于不同业务要求的存取方式
平台业务中,不同的业务有不同的存取要求,比如典型的两大业务用户和订单,用户一般来讲总量是可控的,而订单是不断地递增的,对于用户表首先采取分库切分,每个sharding做一主多读,同样对于订单因更多需求的是用户查询自己的订单,也需要按照用户进行切分订单库,并且支持一主多读。
在硬件存储方面,对于事务日志因是顺序写,闪存的优势比硬盘高不了多少,所以采取电池保护的写缓存的raid卡存储;对于数据文件,无论是对用户或者订单都会存在大量的随机读写操作,当然加大内存是一个方面,另外可以采用高速的IO设备闪存,比如PCIe卡 fusion-io。使用闪存也适合在单线程的负载中,比如主从复制,可以对从节点配置fusion-IO卡,降低复制的延迟。
对于订单业务来讲,量是不断递增的,PCIe卡存储容量比较有限,并且订单业务的热数据只有最近一段时间的(比如近3个月的),对此这里列两种解决方案,一种是flashcache方式,采用基于闪存和硬盘存储的开源混合存储方式,在闪存中存储热点的数据。另外一种是可以定期把老的数据导出到分布式数据库HBase中,用户在查询订单列表是近期的数据从mysql中获取,老的数据可以从HBase中查询,当然需要HBase良好的rowkey设计以适应查询需求。
3) 分布式数据库
对于数据的高并发的访问,传统的关系型数据库提供读写分离的方案,但是带来的确实数据的一致性问题提供的数据切分的方案;对于越来越多的海量数据,传统的数据库采用的是分库分表,实现起来比较复杂,后期要不断的进行迁移维护;对于高可用和伸缩方面,传统数据采用的是主备、主从、多主的方案,但是本身扩展性比较差,增加节点和宕机需要进行数据的迁移。对于以上提出的这些问题,分布式数据库HBase有一套完善的解决方案,适用于高并发海量数据存取的要求。
Ø HBase
基于列式的高效存储降低IO
通常的查询不需要一行的全部字段,大多数只需要几个字段
对与面向行的存储系统,每次查询都会全部数据取出,然后再从中选出需要的字段
面向列的存储系统可以单独查询某一列,从而大大降低IO
提高压缩效率
同列数据具有很高的相似性,会增加压缩效率
Hbase的很多特性,都是由列存储决定的
强一致的数据访问
MVCC
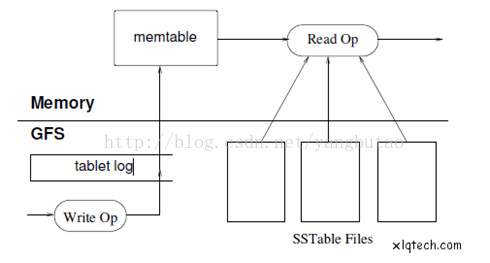
HBase的一致性数据访问是通过MVCC来实现的。
HBase在写数据的过程中,需要经过好几个阶段,写HLog,写memstore,更新MVCC;
只有更新了MVCC,才算真正memstore写成功,其中事务的隔离需要有mvcc的来控制,比如读数据不可以获取别的线程还未提交的数据。
高可靠
HBase的数据存储基于HDFS,提供了冗余机制。
Region节点的宕机,对于内存中的数据还未flush到文件中,提供了可靠的恢复机制。
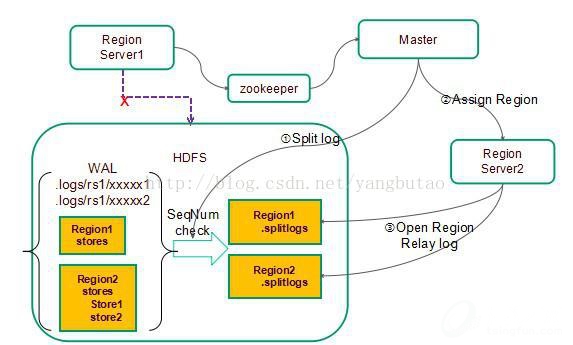
可伸缩,自动切分,迁移
通过Zookeeper定位目标Region Server,最后定位Region。
Region Server扩容,通过将自身发布到Master,Master均匀分布。
可用性
存在单点故障,Region Server宕机后,短时间内该server维护
 有C++难题,加我!
有C++难题,加我!