
需求和现状
行业需求
近年来,随着互联网在全球的快速发展和普及,网民数量的增加,生活中各方面对互联网依赖的增强,带来互联网访问量的爆发性增长。 并且随着web页面内容元素越来越丰富,对交互延时的要求, 给服务端的并发能力和处理能力提出了新的要求。 横向上可以增加机器来提高web服务的可用性和解决并发量的增长。虽然硬件越来越便宜,但是一味增加机器会造成大量的维护成本和非高峰时候资源的闲置。 结合对现有机器的优化和合理的资源配置,提高网络带宽的利用率,才是更有效的解决方法。
现状
当前linux内核的TCP实现存在一些设计和实现上的缺陷, 虽然业界有很多相关的paper和方案,但是社区方面推动比较谨慎和缓慢。 同时随着网络的爆发性增长和C10M概念的出现,基于数据面的实现(绕过内核协议栈)也逐渐成为了业界关注之一。
目标
提高单台机器的新建连接并发能力, 减少访问延时, 提高网络带宽利用率。
单边加速
需要明确的是,本文的目标是tcp加速,目标场景是web server, 而不是路由设备
在峰值带宽的情况下,网络的配置是在高吞吐量和低延时之间的权衡
网卡性能调优
cpu offload
对于大量小包为主cpu密集型场景,可以使用网卡的offload特性,减小cpu的负载,让网卡计算校验和,利用网卡来执行tcp分段, 将小包组装成大包再交给内核协议栈等。可以使用ethtool工具来开启相应特性。
网卡驱动调优
默认的ixgbe配置是在是在高吞吐和低延时之际的权衡, 可以更改相应的硬编码的配置或者ethtool进行更改,对于本文我们的场景来说,意义不是太大
利用网卡MSI-X多队列特性
MSI方式的中断对cpu多核的利用不佳,网卡中断全都落在某个cpu核心上,MSI-X方式可以为每个队列申请一个中断号,然后设置中断亲和性,把该队列的中断映射到某个特定的cpu核心上, 分担了cpu的单核压力。
目前绝大多数网卡都支持该特性,并且该特性是本文其他优化方案的基础条件。
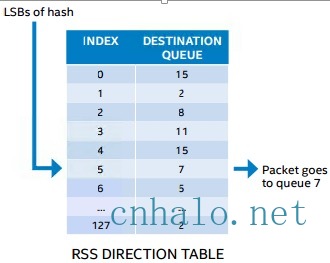
多队列网卡RSS特性
支持RSS的网卡,可以根据TCP头部的某些信息位,比如来源ip端口,目标ip端口等,计算一个hash值,然后通过hash值在一个表里找到该数据要排入的接收队列。
Intel Ethernet Flow Director
RSS解决了cpu的单核心负载高的问题,把不同的数据流分发到不同的cpu上, 但是有可能应用程序并不在该cpu上。
因此Flow Director就是因此而来,它有两种模式:EP(Externally Programed)模式和ATR (automated Application Targeting Routing)模式。
当系统管理员了解整个网络主要的数据包路径的时候可以配置EP模式, 否则应使用默认的ATR模式。ATR模式会采样发送流量,然后根据tcp头的来源与目标信息把数据包交给之前发送该数据流的cpu核心。
Flow Director支持配置一些action, 可以把满足action条件的数据包发到特定的接收队列或者drop。
因此也可以做一些负载均衡和硬件防火墙。
多核优化
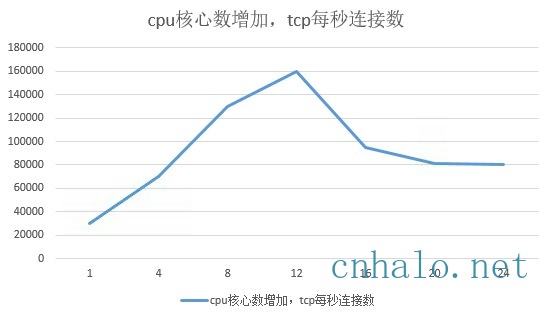
通过上图可以看到随着cpu核心数的增加,tcp每秒连接数并不会线性增长。
因为内核实现的限制,多个核心会竞争一些全局性的锁, 比如listen socket锁,后面会看到具体锁的实现和优化方案。
多核优化原则
通过网卡多队列的支持, 就可以有效利用多核心。
网卡收到数据包后,把相同的tcp数据流发送到同一个cpu上, 同时可以设置应用程序的cpu亲和性绑定到cpu。
这样同一个tcp流都在同一个cpu上处理,大幅度提升cpu cache的命中。
如果服务端开启了irqbalance服务,系统会根据cpu的负载来动态的分发网卡中断,因此如果自己指定整个tcp处理路径,需要停止该服务。
因此多核优化的原则主要如下:
- 相同的数据流在相同的cpu上处理,避免cache bouncing
- 尽量使用percpu本地变量,避免或减少全局锁的粒度
- CPU负载均衡,在保持cpu本地化处理的基础上,避免单核压力过高
RPS/RFS/XPS google patch
RPS(Receive Packet Steering):数据包被网卡RSS发送到对应接收队列后,
RPS就会选择特定的cpu做协议栈处理, 映射关系可以通过/sys/class/net/
RFS(Receive Flow Steering):RFS是在RPS的基础上, 解决了RPS的问题。 当应用程序调用recvmsg的时候,会记录所在的cpu到hash表中,hash表的key是网卡RSS计算的hash值。 因此下一次数据包来的时候就可以直接发到应用程序所在cpu进行处理。
XPS(Transmit Packet Streering):xps维护了发送队列和cpu的映射关系。网卡发送队列发送数据包完成后,可以中断到特定的cpu上, 因此可以让更少的cpu竞争该发送队列,减少中断造成的cache miss减少。
可以通过/sys/class/net/
内核优化
由于目前的linux发行版本依然存在很多TCP方面的性能问题, 因此优化内核是比较直接且有效的方式。
但是需要对内核上游源码持续跟踪,关注bug和新特性,需要长期维护, 并且未来新版本很可能也会推出类似方面的优化patch。
内核新建连接瓶颈
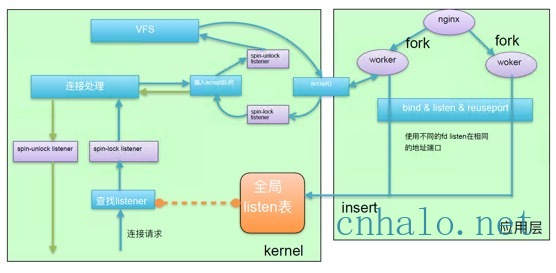
在tcp三次握手的过程中,syn包连接请求会查找全局的一个listen表,找到后就会和应用程序accept的时候竞争该锁。
每个listen socket都有一个accept队列,三次握手完成后会把连接放到accept队列,等待用户程序accept的时候获取listener自旋锁并出队连接,最后通过VFS虚拟文件系统分配文件描述符后返回。
SO_REUSEPORT和SO_INCOMING_CPU
-
REUSEPORT: 每个listener只有一个accept队列, reuseport通过多个不同的socket文件描述符 listen在同一个地址端口,增加可以竞争的锁的数量,提升并发度,避免accept锁和惊群,并且内核提供负载均衡能力。
-
SO_INCOMING_CPU:内核4.4版本提供的socket选项,
如果启用RPS/RFS或者根据网卡的RSS和中段亲和等, 数据包在cpu0上接收, 但是accept()后, 使用在cpu1上的reuseport listener,
accept()后通过调用SO_INCOMING_CPU选项就能得到数据包被处理的cpu, 这时候应用程序做一定的调整,比如说把这个socket分发到绑定到该cpu上的worker进程处理。
这样就不需要通过启用rps/rfs,来发送IPI中断,在协议栈的层次变更处理路线。 尤其在长连接中,应该有较好的性能提升。1
getsockopt(fd, SOL_SOCKET, SO_INCOMING_CPU, &cpu, &len);
SO_ATTACH_REUSEPORT_EBPF和SO_ATTACH_REUSEPORT_CBPF
如上述SO_INCOMING_CPU需要应用程序调正处理逻辑, 那有没办法直接在reuseport选择listener的时候直接选择当前协议栈所在cpu上的reuseport listener呢?
通过SO_ATTACH_REUSEPORT_EBPF和SO_ATTACH_REUSEPORT_CBPF选项可以指定自己reuseport算法。
内核4.4 lockless listener
老版本的内核,在每个listener里都有一个request队列,每收到一个syn包后都要锁listener并创建一个新的request插入。 4.4版本在listener之外维护了request,使用tcp的ehash表,这样就大幅度减少了listener锁的竞争。
Fastsocket
- Fastsocket是新浪开源的,并在生产环境部署的一个内核优化版本
- 使用的时候,只需要启动时指定LD_PRELOAD环境变量,使用它的动态库来替换原生socket接口。 容易回滚到原生接口。
- 基于centos-6.5, kernel 2.6.32版本,(对docker支持不好,高版本内核发行版使用systemd管理服务,不容易降级)
- 根据官方报告,跟原生centos-6.5相比,提升260%-620%(24核以上)
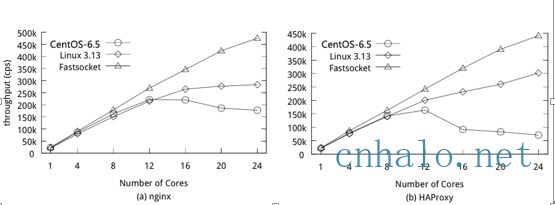
Fastsocket架构
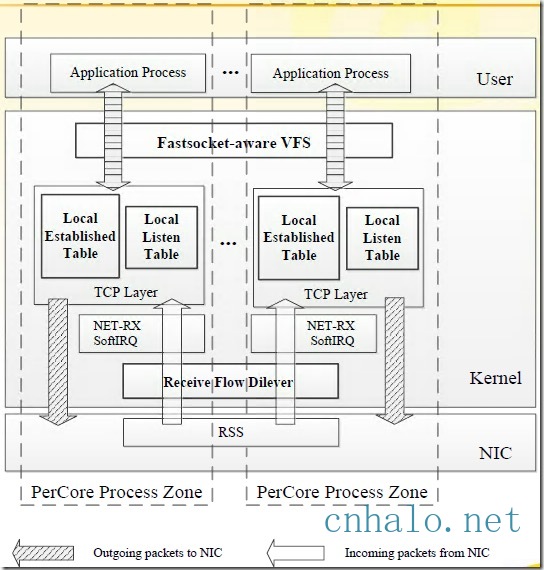
上图可以很清楚的看到, 它也是利用本文前述的技术原理和多核优化原则。
- 通过在网卡多队列RSS, 使用flow director或者google的rps/rfs/xps把数据包都发送到应用程序所在的cpu上,应用程序启动时也设置cpu亲和性绑定到特定的cpu上,让相同的数据流都在同一个cpu上处理。
- 每个cpu维护一份本地的Established表和Local Listen表, 在reuseport的基础上,进一步减少listener锁的竞争。
- 优化VFS文件系统,因为socket不需要inode和dentry,可以忽略一些需要同步的代码路径。
Fastsocket优化收益
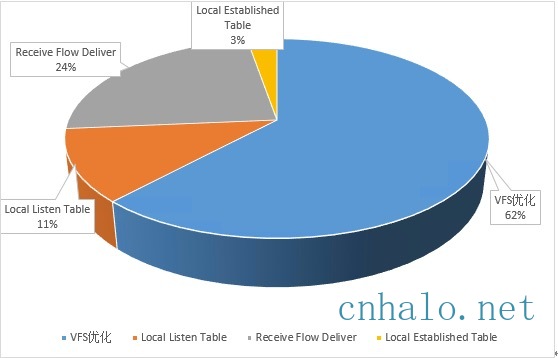
可以看到VFS的优化空间很大,其次多核tcp路径的优化,然后是增加cpu本地listen表。
使用数据面方案-绕过内核协议栈
内核本身不可避免的开销
- 系统调用,陷入内核态,上下文切换
- 内核态到用户态的数据拷贝
- 中断处理
还有诸如不容易调试, 代码比较复杂等等都会增加开发和维护难度。
使用DPDK
- DPDK是intel推出的快速的数据包处理框架
- 通过内核uio机制,使数据包直接dma发送到用户态内存中
- 因为不走内核协议栈,需要结合其他用户态协议栈一起使用
- 支持intel网卡,其他网卡支持有限
- 根据官方数据转发一个包大概80个时钟周期(一次ddr3访问就需要近200个时钟周期)
基于DPDK的应用架构
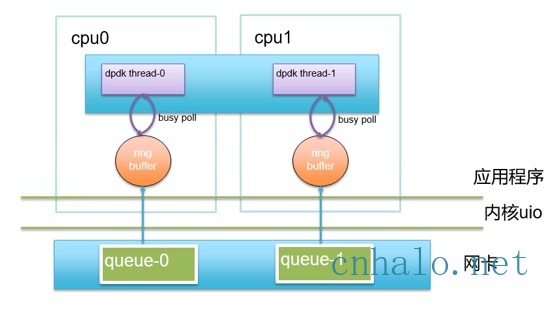
上图可以看到dpdk应用为每个网卡队列启动了一个线程,每个线程绑定到一个cpu上, 通过内核的uio驱动机制,网卡队列的数据包可以直接发送到用户态的缓存中,然后dpdk线程循环拉取该缓存,之后递交到用户态协议栈处理。
DPDK的内存优化
- 所有内存资源启动时一次性分配完毕
- 支持numa, cpu就近分配内存
- 使用hugepage,减少tlb miss的时候,访问多级页表的开销
- 在cache line的基础上,支持多通道和内存条rank级并行优化。一个内存通道一般使用64位数据总线,双通道同时工作提供了128位传输能力。Rank是指DIMM上几个内存颗粒共同提供的64位数据,同一条内存上的不同rank因为共享数据总线而不能被同时访问,但内存可以利用交错的片选信号来访问不同rank中数据。

上图可以看到通过数据包对象位于不同的channel和rank, 使对象并行加载。
支持DPDK的用户态协议栈问题
- 有mtcp,seastar等等
- 接口不兼容, 分配的fd描述符不是内核分配的,不能和内核文件接口通用。 比如mtcp实现的epoll就不能加入内核文件描述符。因此大多数开源软件要转到dpdk协议栈接口就有这方面的设计问题。
- 生产环境稳定性有待验证
- 因为不走内核了,不支持netstat等工具链
总之做tcp webserver的考虑各方面研发运维成本,目前使用dpdk并不十分合适
DPDK DNS缓存系统
虽然DPDK的tcp协议栈有比较多工作要做,但是目前DPDK在网络监控快速的数据包分旁路阻断, 或者在DNS方面还是有很多公司在跟进。
我们可以利用DPDK来做一个DNS的缓存系统, 实时解析DNS的数据包,其他所有的包或者缓存中未命中的包都通过kni机制重新走内核协议栈。 既利用了DPDK快速处理能力,又避免了DPDK在TCP协议栈方面的坑。
但是写本文的时候kni只支持单队列,需要修改底层模块来进行支持
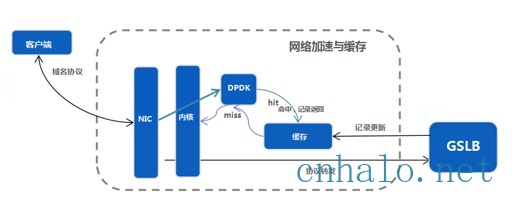
- 通过DPDK收到本机DNS请求的包后,解析请求,查询缓存(无阻塞)。
- 所有非本机DNS查询的数据包或缓存未命中的包,通过DPDK的kni机制,重新走内核协议栈。(会增加一点延时,但是通过缓存的高命中率确保整体的收益非常高)
拥塞控制
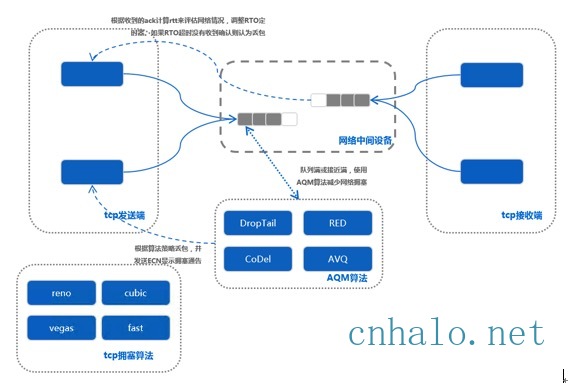
拥塞控制是分布式异步算法来共享带宽,它有两部分组成:
- TCP:发送窗口=min(rwnd, cwnd)
- AQM:网络中间设备调整和反馈拥塞信息,在高吞吐和低延时之间做出平衡,如设备队列满主动丢包等
期望达到一个高吞吐,公平,稳定的带宽利用
传统拥塞算法弊端
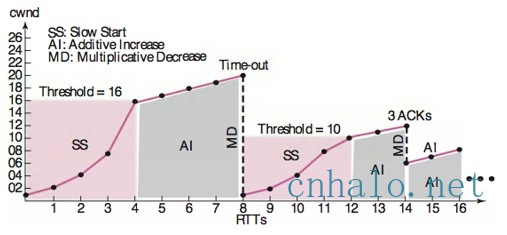
- 慢启动,指数增加(有可能被推迟确认),http/2.0通过减少连接数来避免慢启动,上图经过4个RTT时间cwnd从1个MSS增加到慢启动阈值16
- 增加到慢启动阈值后,线性增加慢。 在一个RTT时间内收到所有确认只能增加1个MSS
- 丢包的后阈值减半,重新进入慢启动,空闲一个重传超时RTO后也会重新慢启动(net.ipv4.tcp_slow_start_after_idle=1), 抖动非常严重
- 收到3个相同ACK后,会进入快重传阶段,不降低阈值,线性增加
上述算法是把丢包作为拥塞信号,但是丢包不一定拥塞, 比如在无线/移动环境中。 并且经常性的慢启动和降阈值造成的抖动,造成带宽利用率大幅度降低。
如何优化拥塞算法
- 增加延时作为拥塞反馈信号
- 建立更好的数学模型, 更快达到网络最大利用率(减少慢启动和线性增加所做的逐步探测网络带宽的过程)。
根据丢包和延时动态计算一个网络的均衡点(在这个点实现了网络利用率的最大化,并且能尽量保证各方的公平性)。 离均衡点越远,拥塞窗口调整越快, 否则越慢。
以上就是FAST TCP的思路。
FAST TCP
- FAST TCP首先被Fastsoft公司商业化,后被Akamai收购。
- Akamai是全球最大cdn服务商,承载全球15%-30%流量
- 需要稳定性公平性等多维度测试, 确定经验值的选取
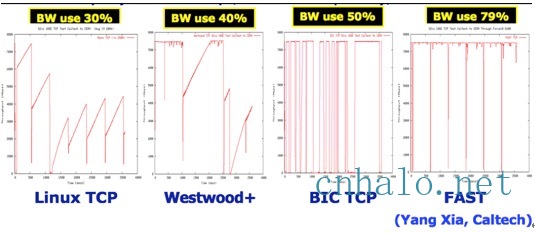
以上可以看到FAST TCP的带宽利用率最高,抖动最少。
Zeta TCP
- 华夏创新推出的基于传输历史学习的算法
- 成功案例: 爱奇艺,蓝汛cdn/腾讯视频
- 适用于网络链路比较差或延迟带宽积比较高的网络环境(导致大量国外vps的客户购买), 并且需要大部分tcp包在50kb以上的场景, 否则效果更差。
Google BBR
- google bbr算法已经被merge到linux 4.9中,并且效果不错,并经过Google大规模测试
- 主要的缺点就是新版内核的拥塞框架回调点和旧版本有很大区别,并不容易移植到低版本
双边加速
由于内核TCP实现的以上各种问题,所以目前大多数双边加速都是在UDP的基础上,增加应用层的TCP的可靠性机制(确认,重传,按序等等)。
因为客户端和服务端都需要调用该协议SDK, 如果要对现有的软件接入该SDK,基本上需要对软件进行重构和重写, 因此开发成本还是比较大的。
QUIC
可以认为是tcp+tls+http/2.0在udp上的实现,目前是chrome上的实验特性, 仍处于快速迭代过程中。
https://www.chromium.org/quic
UDT
Yunhong GU(tech lead of google public dns)实现的一个reliable udp。
http://udt.sourceforge.net
MPTCP
也就是MultiPath TCP
kcp
https://github.com/skywind3000/kcp
也是一个udp隧道
这些自己玩玩就好了,在生产环境中使用需要谨慎。
本文作者: bhpike65
本文链接: http://www.cnhalo.net/2016/03/13/tcp-accelerate-report/
 有C++难题,加我!
有C++难题,加我!