

此时若后台采用的是JAVA编程,问题便很容易解决直接用destStr = new String(sourceStr.getByte(“UTF-8”), “EUC-JP”)就可以进行编码的转换,不过C++就没那么幸运了,除非按照一定的逻辑自行实现一套编码转换的方法,当然从各方面限制来看是不太现实的。
因此,要解决此问题,需对字符集编码的原理一探究竟:
相同的二进制内容,不同的编码环境下显示不一致:
unsigned char j = 0xa1;
for(; j < 0xdf-30; j++)
{
char p[1024];
sprintf(p, "%d\t%02x\t%o\t%c \t %d\t%02x\t%o\t%c", j,j,j,j, j+31,j+31,j+31,j+31);
std::cout << p << std::endl;
}
(整形,十六进制,八进制,字符型)前面0-127个是ASCII标准的编码,后128-255是拓展ASCII编码,在日文操作系统默认编码为shift-jis的环境中日文的半角片假名由拓展ASCII的0xa1-0xdf表示。中文操作系统则完全不同,要表示日文半角片假名必须使用日文的编码方式(EUC_JP或shift-jis)。
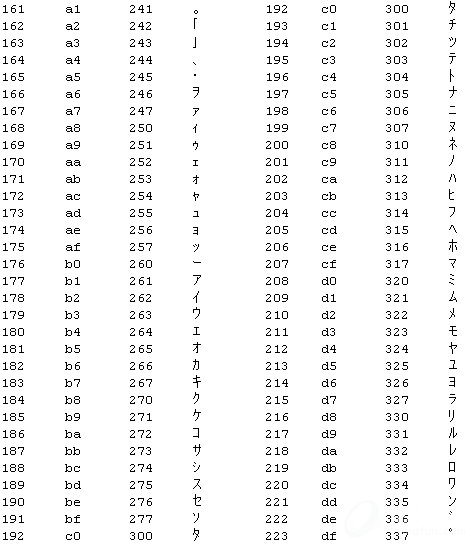
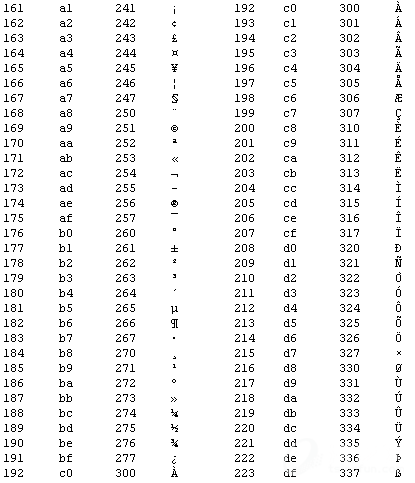
显示同一字符,不同编码环境下二进制内容不一致:
void printStringByChar(std::string &str) {
char *p = const_cast<char *> (str.c_str());
char q[1024];
while (*p != '\0') {
sprintf(q, "%02x, %u, %c", *p, *p, *p);
std::cout << q << std::endl;
p++;
}
}
(十六进制,无符号整形,字符型)
Shift-jis:
0xffffffb1, 4294967217, ア
Euc-jp:
0xffffff8e, 4294967182, ?
0xffffffb1, 4294967217, ア
Utf-8:
0xffffffef, 4294967279, ?
0xffffffbd, 4294967229, ス
0xffffffb1, 4294967217, ア
综上,不同的编码环境拥有其独有的编码规则,对二进制的内容解析结果不尽相同。而不同的平台往往其编码环境又是不同的,如中文系统默认GB2312,Windows日文系统默认shift-jis,Linux日文系统默认euc_jp,英文系统默认utf-8等。所以解决以上问题关键在不同平台下编码的一致性上,所以解决该问题不外乎两种思路:
1.从前台传入euc_jp编码的内容,但是不能破坏前台页面编码的一致性即UTF-8,经过查找资料发现可以实现,代码如下:
<form method="post" action="..." accept-charset="EUC-JP">
......
......
// firefox下为 document.characterSet 仅支持读取
// ie/safria/chrome/opera 下为document.charset 并且支持读写
var charset = document.charset;
document.charset = 'EUC-JP';
document.form.submit();
document.charset = charset;
以上代码的确能够在不改变页面编码的情况下,将页面以制定的编码方式传入后台,但是euc_jp编码的内容在后台以相同编码形式存储后,文件查看完全正常,但是当内容被再次读入UTF-8编码的页面上时,又出现了乱码。因此在后台读取文件内容后必须再将euc转换为utf-8,由此看来此方案不可取。2.前台后台保持一致的编码方式即UTF-8,虽然后台文件查看会出现乱码,但是读取到前台以UTF-8解码时显示完全正常。这时就必须相应的修改匹配的正则表达式了,因为它是针对EUC的,现在要将其改为UTF-8。
通过以上显示字符的十六进制内容的方式,如果知道了半角片假名的范围就能知道它们对应的字节内容了,。。。。。。(按照EUC的x8ea1-0x8edf的范围,UTF-8形式是以三字节表示的, UTF-8使用可变长度字节来储存 Unicode字符,例如ASCII字母继续使用1字节储存,重音文字、希腊字母或西里尔字母等使用2字节来储存,而常用的汉字就要使用3字节。辅助平面字符则使用4字节)。当然如果用抓包工具分析可以发现页面发送的实际内容以同样的十六进制形式传入后台(不过0x被%代替),这样就能保证所有的半角片假名能够匹配通过。
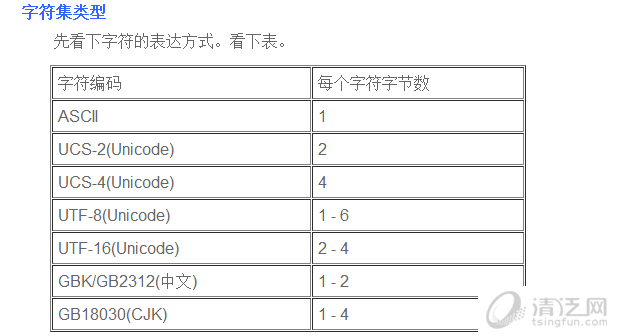
以8位为基本单位,用1-6个8位来存储一个字符。
UTF-32 UTF8
0x00000000 - 0x0000007F 0xxxxxxx
0x00000080 - 0x000007FF 110xxxxx 10xxxxxx
0x00000800 - 0x0000FFFF 1110xxxx 10xxxxxx 10xxxxxx
0x00010000 - 0x001FFFFF 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
0x00200000 - 0x03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0x04000000 - 0x7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
ANSI字符集
l 各个国家的ASCII码的扩展统称为ANSI字符集。
问题到此仍然没有结束,既然表单中输入的片假名能以页面的编码UTF-8提交,但是如果上传的文件中含有片假名时,新的问题便又出现了,因为文件的内容原样传入后台没有也不可能经过form的转码,而我们需要的是UTF-8编码的文件内容,否则其他编码的片假名验证仍然无法通过,而上传的文件默认就是ANSI(Win日文即shift-jis,Win中文gb2312等)编码的。
解决以上问题,就必须将文件进行转码,转化为UTF-8的编码,但是转码后又发现新的问题,文件的首行内容读取后匹配失败(输入的内容肯定是正确的),原来UTF-8文件分为有BOM和无BOM两种,所谓的BOM(Byte Order Mark),是UTF编码中的一个标记,文件开头添加了三个字节OxEF 0xBB 0xBF。这个标记是可选的,因为UTF-8字节没有顺序,所以它可以被用来检测一个字节流是否是UTF-8编码的,Windows可以根据这个标识决定是否以UTF-8形式打开文件。在将文件转换为utf-8编码时会有一个选项选择有无BOM,不过不了解的人可能不容易察觉,也就忽略了此选项。
当然对上传的文件作这样的限制,势必会降低客户体验,不过或许也只能这样,然后将要注意的问题详细写入用户手册。
为什么会乱码?
字符在保存时的编码格式如果和要显示的编码格式不一样的话,就会出现乱码问题。
我们的Web系统,从底层数据库编码、Web应用程序编码到HTML页面编码,如果有一项不一致的话,就会出现乱码。
所以,解决乱码问题说难也难说简单也简单,关键是让交互系统之间编码一致。
使用哪些字符。字符包括文字、标点、图形符号、数字等。这个集合叫做字符集;
如何进行存储。规定字符集中的每个字符分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定叫做编码。
charset ,字符集,也就是某个符号和某个数字映射关系的一个表,(imjacob注: 这种说法有待商榷,和 编码有什么区别呢?个人感觉文章的说法比较准确)也就是它决定了107 是koubei 的 ‘a’,21475 是口碑的“口”,不同的表有不同的映射关系,如 ascii,gb2312,Unicode. 通过这个数字和字符的映射表,我们可以把一个二进制表示的数字转换成某个字符。
 有C++难题,加我!
有C++难题,加我!